調査分析レポート
論文データを活用した共同研究者探索プロセスの提案
~生成AIによるデータ処理の可能性~04考察著者:中辻 裕 株式会社ジー・サーチ
考察
所属機関ランキングとネットワーク図を作成することで、本テーマに精通する研究機関と主要な研究者を特定することができた。このデータは研究者を探索する際に有益な参考情報となると考えられる。

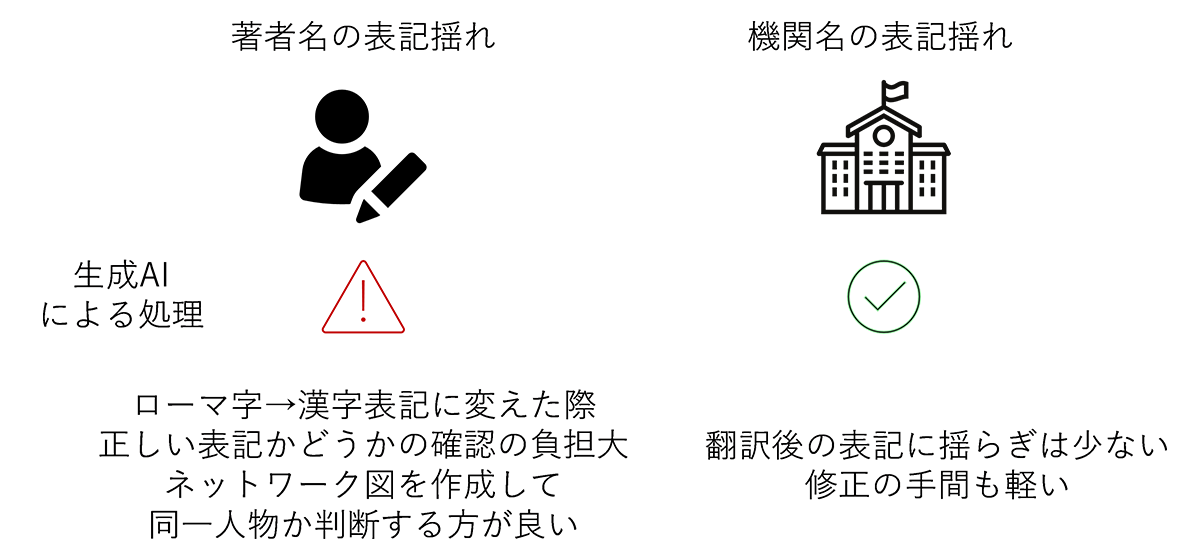
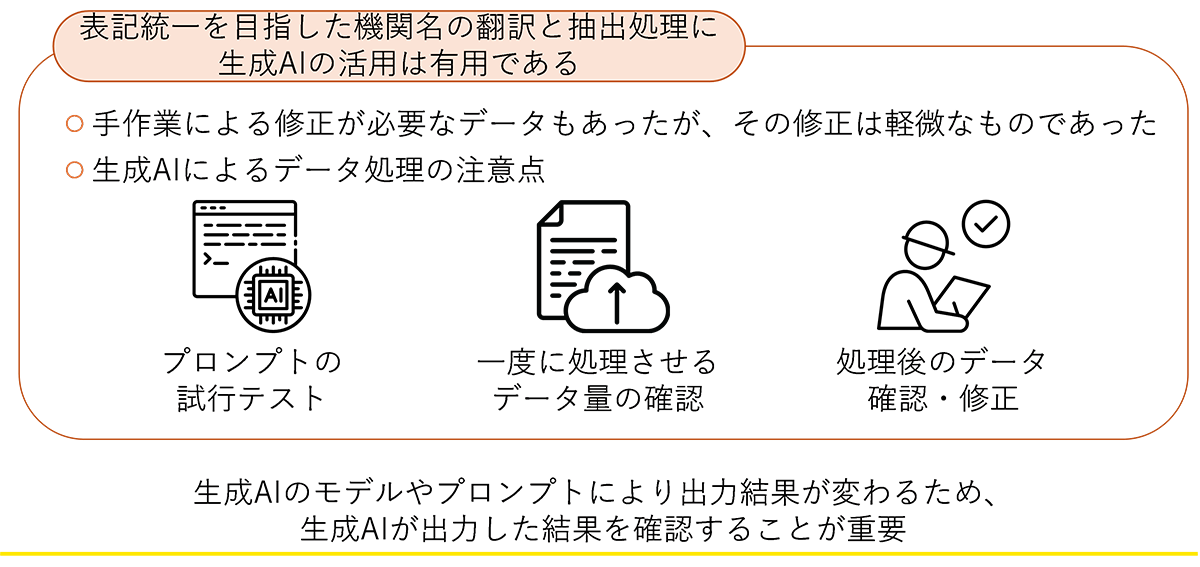
また、抽出した論文データに対して生成AIによる機関名の抽出と翻訳については、手作業による再修正が必要なデータも散見されたが、その修正は軽微なものであった。そのため、数百件程度の論文データであれば、表記が統一されていない機関名の抽出と翻訳処理について、生成AIの活用は有用であると考える。その一方で、以下に示すような、生成AIによるデータ処理の注意点も明らかとなった。
- 作成したプロンプトが正しく機能するかどうかを確認する試行テストを要すること。
- 一度に読み込ませるデータ量の調整が求められること。378件のデータを一度に処理させると、出力途中に処理が停止してしまうことがあった。試行しながら、読み込ませるデータ量を決定する必要がある。
- 出力結果を確認し、適宜手作業による修正を行う必要があること。本研究では、機関名の出力結果を確認し、手作業による修正を加えた。生成AIのモデルやプロンプトにより出力結果が変わるため、生成AIが出力した結果を確認することは重要であろう。
最後に、論文データのデータ処理に関する課題を整理する。本研究では、著者名表記の揺らぎの修正に当たっては、生成AIを用いても、修正された氏名の正確性の確認に時間を要すると判断した。そのため、生成AIによる処理は行わず、ネットワーク図から同一人物であるかどうかの判定を行った。このことから、著者名表記の揺らぎに関しては、分析の目的に応じて実施するかどうかを検討することが望ましいと考えられた。一方で、機関名表記の修正に関しては、生成AIの出力結果を加工することで手作業による負荷を軽減することができた。しかし、いずれにせよ、処理データが多くなる場合には、生成AIのプロンプトを見直し、修正が必要なデータのみを再度処理させる等の検討が必要だろう。